 |
|
Уважаемые коллеги,
Большое спасибо организаторам и Константину Ильичу Могилевскому за приглашение принять участие. Готовясь к этому выступлению на конгрессе молодых ученых по захватывающей теме Искусственного Интеллекта, невольно возвращался в мыслях к годам своей собственной юности. В первой половине 80х годов прошлого века сразу после окончания школы я пошел работать лаборантом в Информационный отдел крупного научного-исследовательского института. В то время в кабинете историка наиболее продвинутым технологическим устройством была электрическая печатная машинка, а я работал в качестве человеческого Гугла - исследователи давали мне темы
|
| |
|
своих исследований, названия организаций, событий или имена, которые их интересовали, а я тратил дни и недели напролет в библиотеке бегло просматривая толстые подшивки ежедневных газет и бесчисленное количество журналов и книг в поиске необходимой им информации.
Поэтому большой радостью и неоценимой помощью в этой информационной работе стало появление компьютеров, сканеров а затем и Интернет в начале 90х годов. Был тогда потрясен, что работу, на которую приходилось тратить несколько часов ежедневно, стало возможно делать более качественно и за секунды путем сканирования и распознавания изданий и добавления к ним полнотекстового поиска. А доступ к коллекциям стал возможен мгновенно из любой точки земного шара по Интернет. До сих пор нахожусь под впечатлением от этих блестящих технических возможностей и продолжаю ими заниматься уже сколько лет так как они продолжают революционизировать доступ исследователей к информации и работу с ней. И вот, тридцать лет спустя, технический прогресс продолжается и мы обсуждаем с вами новые возможности зарождающегося Искусственного Интеллекта.
Вместе с тем, данная тема не является новой, однако в последние годы ИИ привлекает особенно повышенный интерес, включая в области его применения в архивах. Работа здесь идет в разных направлениях, и соответственно специалисты дают иногда разные определения ИИ в зависимости от их конкретных направлений исследований и разработок.
|
В частности, среди популярных направлений можно упомянуть:
- Создание и обучение программ для автоматического вычленения из текстов имен и названий организаций, географических названий. Перевод аудиозаписей в текст, автоматизация поиска и распознавания в больших базах данных имиджей и видео файлах.
- Разработка механизмов обработки больших массивов данных, автоматизированной экспертизы ценности, в частности, материалов электронной переписки - эта тема особенно сейчас популярна у западных архивистов.
- Распознавание рукописных текстов - здесь стоит упомянуть интересный опыт, полученный в проекте Российского исторического общества и Сбербанка «Digital Петр».
- Создание чат ботов с искусственным интеллектом (ChatGPT).
|
 |
|
- Компьютерные гиганты типа Майкрософт и Гугл экспериментируют с использование ИИ для написания программного кода.
- Растущей проблемой в США, например, становятся студенты, пишущие курсовые работы с помощью таких программ Искусственного Интеллекта как GPT-3.
- Большое внимание на нашем конгрессе уделяется и перспективам использования Искусственного Интеллекта в области НИОКР в разных областях знаний, и так далее.
При всем при этом следует оговориться, что разные программы Искусственного Интеллекта показывают результаты разного качества, которые кого то побуждают еще более активно исследовать и улучшать работу в этом направлении, а кого то укрепляют в их скептицизме.
- Однако в этом году мы наблюдаем буквально расцвет рисующих и иллюстрирующих программ из категории Generative AI или Генерирующего Искусственного Интеллекта, которые переводят текстовые запросы в имиджи, видео и звук как, например, Stable Diffusion, Midjourney и DALLE 2.
Новые возможности здесь кажутся захватывающими - я также не смог удержаться и попробовал работу программы DALLE 2 для производства двух иллюстраций, которые мне потребовались для выступления на другой конференции в прошлом месяце.
|
|
 |
Первую слева я использовал для иллюстрации библиографов, создающих карту информационной вселенной, а вторая должна была иллюстрировать информационную вселенную российской государственной библиографии и сопровождалась призывом к слушателям уделять больше внимания исследованию "черной материи информационной вселенной" или редким или совсем неизвестным документам. Я ввел текстовый запрос на эти имиджи в программу Далли и она нарисовала их за 10 секунд каждый. Эти примеры демонстрируют впечатляющий прогресс ИИ в области иллюстрации и визуализации контента.
|
|
| Должен признаться, что еще недавно скептически относился к той идее, что искусственный интеллект в какой то момент может вторгнуться в такую чисто человеческую область как творчество. Последнее еще недавно казалось доступным только человеческому сознанию, а не машинному. Но вот последние опыты с программами Генерирующего Искусственного Интеллекта возможно заставят нас в будущем несколько переоценить возможности ИИ и в такой чисто человеческой области как творчество. |
| |
|
Но возвращаясь все же к вопросу об улучшении доступа исследователей к архивным коллекциям и цифровой трансформации архивов в следующее десятилетие, хотел бы упомянуть некоторые проблемы, разрешение которых более чем искусственного интеллекта потребует живого человеческого интеллекта, смекалки и инициативы архивных специалистов. В частности, речь идет о таких характерных проблемах в архивной отрасли как:
- Стихийность оцифровки - архивам иногда трудно определиться в приоритетах - для кого делается оцифровка и как будут использоваться ее результаты.
- Проблема устаревшего программного обеспечения и баз данных, которые усложняют задачу улучшения онлай-доступа исследователей к коллекциям.
- Как заметил один архивист на встрече в прошлом году - “архивное пространство центрального фондового каталога напоминает период феодальной раздробленности, где каждый архив держит свою вотчину. Полнота представленной информации из архивов отличается, и размещается там иногда с большим опозданием”.
- Отвечая на вопрос “Почему медленно создаются базы данных?” архивисты говорят о том, что не хватает рабочих рук, и что это является особенно острой проблемой у региональных и муниципальных архивов.
- В некоторых случаях архивисты с тревогой отмечают падение посещаемости архивных веб сайтов и интернет-выставок, и т.д.
Что меня здесь беспокоит, в частности, так это выбор приоритетов для расходования весьма ограниченных ресурсов, которые направляются на развитие архивной системы и улучшения доступа к ней исследователей. Нам необходимо убедиться, что за занятиями популярными веяниями, в частности в области ИИ, мы не на минуту не ослабим внимания к важным текущим потребностям исследователей.
А что нужно непосредственно историкам?
Их подавляющее большинство продолжает из года в год просить о достаточно простых вещах:
- оцифровывать нужные им для работы но труднодоступные документы
- улучшать интернет-доступ к архивным коллекциям и
- предоставлять простые и удобные в использовании интерфейсы для работы с оцифрованными коллекциями желательно с полнотекстовым поиском и научно-справочным аппаратом, который помогает им видеть взаимосвязи между родственными документами.
Слайд ниже я сделал несколько лет назад в качестве памятки о некоторых предпочтениях исследователей в области доступа к архивным коллекциям (безусловно их потребности в электронной области не ограничиваются упомянутыми на слайде):

|
|
С учетом сказанного, я бы ответил на поставленные перед панелистами вопросы о том, “Каким образом все перевести в «цифру»?” и "Идет ли в России «цифровой поворот» в истории в нужном направлении?" следующим образом:
- Необходимо как можно быстрее переводить оцифровку в архивах от фрагментарной работы, которая происходит от проекта к проекту, в область программной работы. При программном подходе процессы отбора материала для оцифровки, его обработка и онлайн-публикация постепенно интегрируются в ежедневную будничную работу архива.
- Архивистам необходимо более плотно работать непосредственно с историками, формировать с ними рабочие группы, и в деталях обсуждать и совместно планировать создание указанных программ по оцифровке и определять их приоритеты.
- Также думаю, что как архивистам, так и производителям программного обеспечения для доступа к оцифрованным коллекциям, необходимо осознавать большую и растущую проблему для исследователей, а именно - перегруженность информацией. В этой ситуации человеческий интеллект следует “Правилу наименьшего усилия”, которое гласит:
“Большинство исследователей (даже “серьезные” ученые) проявят склонность к использованию легко доступного источника информации, даже если этот источник относительно низкого качества и далее, скорее всего, исследователи останутся удовлетворены тем, что им было легко найти по сравнению с использованием источников более высокого качества, работа с которыми требует от них больше усилий... Следуя общему правилу, люди предпочитают кажущуюся легкость доступа качеству содержания, когда они выбирают себе источник или канал информации”.
Поэтому, если мы хотим привлекать пользователей к электронным архивным коллекциям, мы должны обеспечить их быстрыми и удобными для работы интерфейсами, иначе они будут их избегать в пользу более дружелюбных источников информации, даже если они содержат менее качественную информацию.
Отвечая на последний вопрос сегодняшней встречи - "Как я представляю себе будет выглядеть Архивный фонд Российской Федерации через 10 лет?", хотелось бы предположить следующее:
- На веб сайтах архивов будут присутствовать детальные описания фондов и подробные описи дел, а наиболее востребованные коллекции и документы будут доступны историкам по Интернет где то в виде образов, а где то и с полнотекстовым поиском на удобных и быстрых интерфейсах.
- Большинство архивов, и прежде всего федеральные, но по возрастающей и региональные и муниципальные архивы, внедрили оцифровку и онлайн-публикацию все большего числа документов в свою будничную деятельность и в согласовании приоритетов этой работы с исследователями и своими пользователями.
- Родственные федеральные, региональные и муниципальные архивы наладили между собой тесное сотрудничество с целью создания межархивных каталогов, баз данных и научно-справочного аппарата, которые позволяют делать поиск и находить требуемые информацию и документы сразу во многих архивах.
- Также мечтаю о том дне, когда архивы и библиотеки смогут смелее развернуть свое лицо непосредственно к исследователям, и перейти от их пассивного обслуживания к активному, при котором архивы смогут вести и учитывать профессиональные профили и интересы индивидуальных исследователей, и проактивно рассылать нужные им информацию и документы по имейлу или складывать их в личные кабинеты в соответствии с исследовательскими профилями по интересам.
|
| Заключение - Электронная библиотека исторических документов |
| |
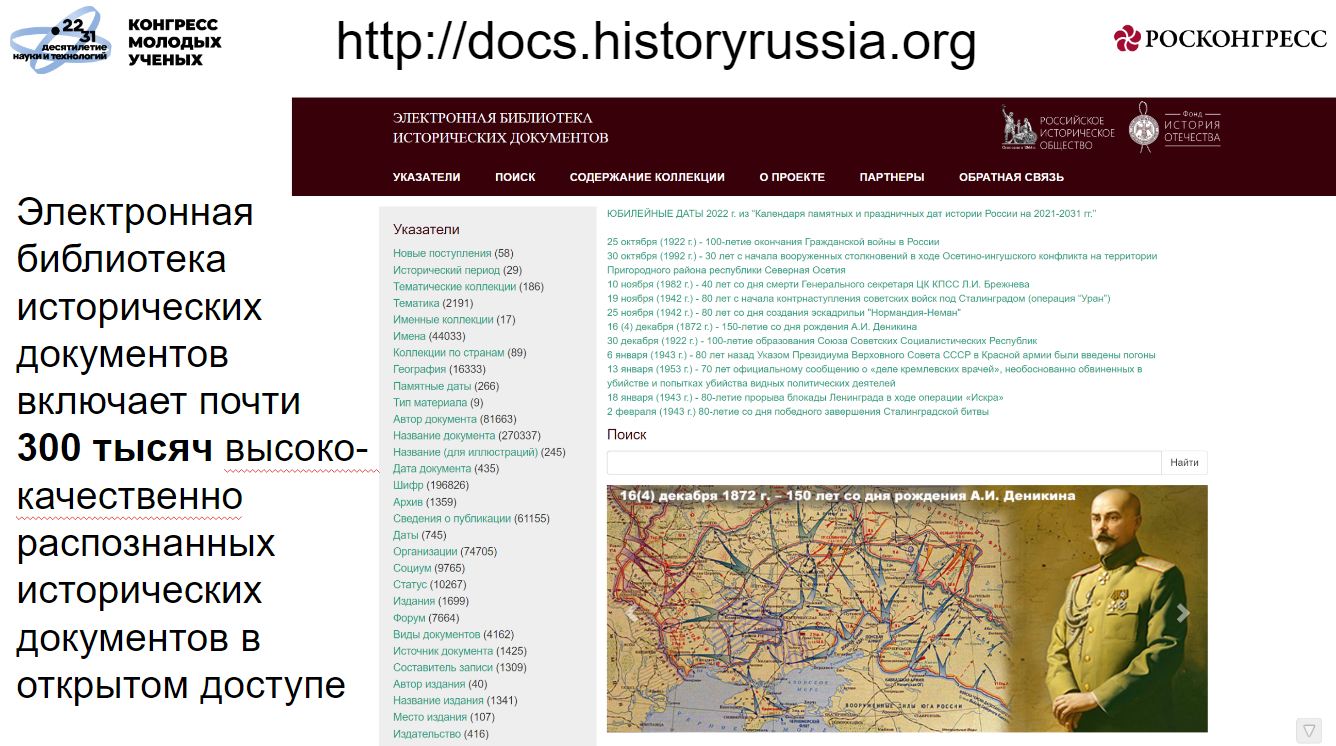
| В заключение хотел бы упомянуть проект “Электронная библиотека исторических документов Российского исторического общества” которая является быстрорастущей коллекцией, включающей на сегодня почти 300 тысяч текстов хорошо распознанных документов по истории России. Это потенциально прекрасный материал для экспериментов в области автоматической обработки и индексации текстов, а также применения перспективных технологий Искусственного Интеллекта в исследовательских целях. Мы приглашаем заинтересованных специалистов связываться с нами и обсуждать любые идеи в этой области. Проект Электронная библиотека исторических документов открыт для сотрудничества. |
 |
Примечания:
* Панель прошла в формате вопросов и ответов. Видео-запись по адресу: https://roscongress.org/sessions/kmu-2022-glubina-istoricheskoy-pamyati-i-iskusstvennyy-intellekt/translation/
Источники:
Архивы/Библиотеки и Искусственный Интеллект / Archives/Libraries and Artificial Intelligence (ноябрь 2022 - 2023 гг.)
|
| |
